Verse Detection Pipeline
Four complementary strategies that turn live sermon audio into matched Bible references — direct, semantic, quotation, and reading mode — merged by an ensemble pass.
Rhema's detector doesn't bet on a single signal. Pastors cite scripture in many ways — exact references ("First Corinthians 13:4"), paraphrases, partial quotations, or by simply moving through a chapter — and a single technique misses too many of them. The detector runs four strategies in parallel and merges their outputs through an ensemble pass.
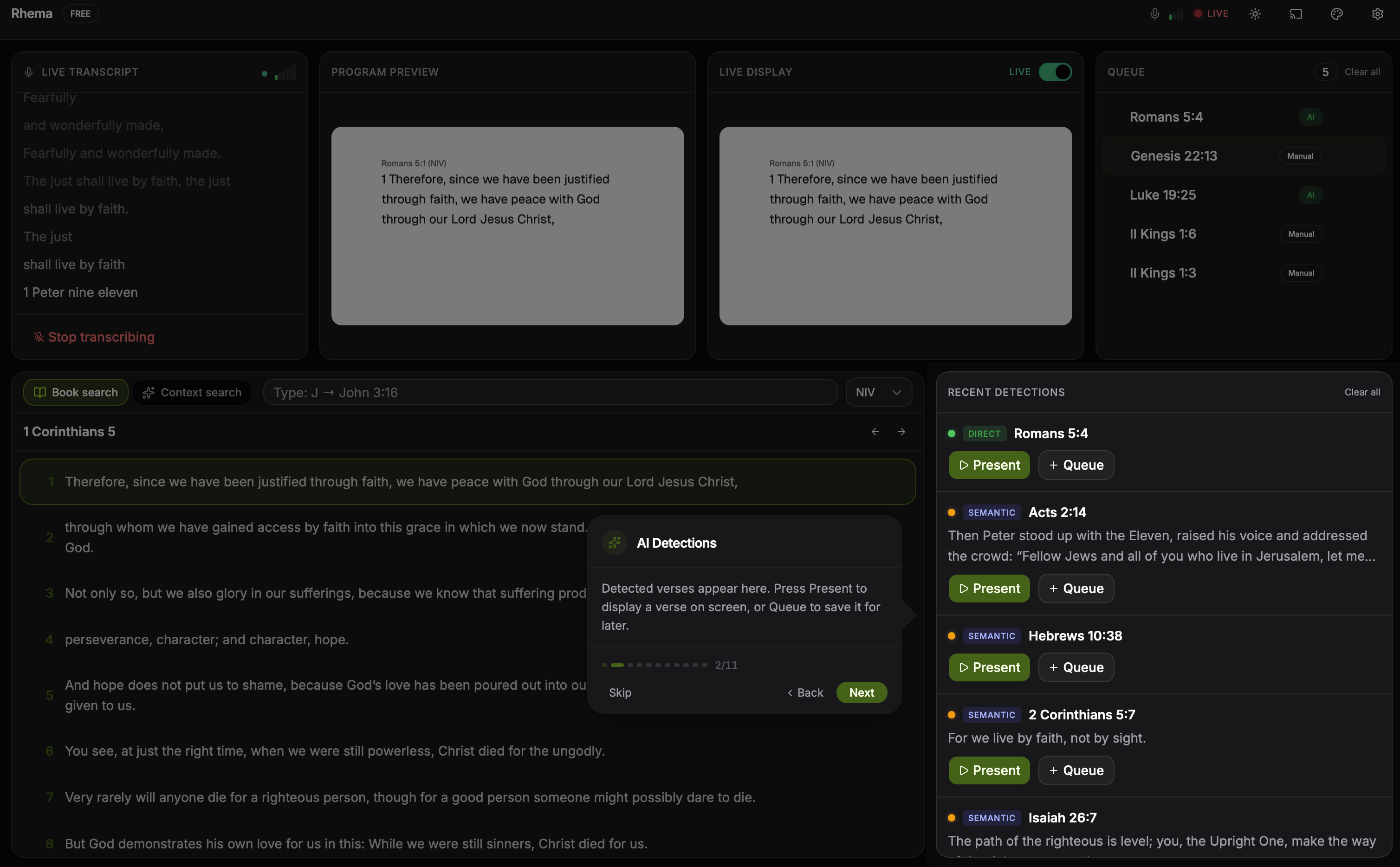
The detections panel during a sermon: each card shows the matched verse, the strategy that surfaced it (direct, semantic, quotation, or reading mode), the confidence score, and the transcript snippet that triggered the match. Click to expand.
The four strategies
Direct reference parsing
A precompiled Aho-Corasick automaton (aho-corasick = "1" in
rhema-detection) scans the transcript for canonical book names and
abbreviations. When a hit is followed by a chapter/verse pattern, the
detector emits a high-confidence reference.
Fuzzy matching catches misheard book names ("Galatian" → "Galatians", "Psalmon" → "Psalms") so transcription noise doesn't sink an obvious cite.
Semantic search
Verses that aren't named — paraphrases, lyrical references, applied
teaching — are caught by a vector retrieval pipeline. The
Qwen3-Embedding-0.6B model (exported to INT8 ONNX during
setup:all and run via the ort Rust crate) embeds every verse,
and a brute-force cosine-similarity scan over ~31k vectors at
1024 dims returns nearest neighbors in a few milliseconds on a
modern CPU.
The file is named hnsw_index.rs for historical reasons, but the
implementation is currently brute-force — the dataset is small
enough that an HNSW index isn't needed yet.
The semantic strategy runs on a sliding window over the transcript so a phrase that lights up halfway through a sentence still triggers a match.
Quotation matching
When a pastor quotes scripture verbatim — even partial sentences — the quotation matcher checks the transcript window against the indexed verse text directly. This catches things the embedding model is too coarse for, like "the just shall live by faith".
Reading mode
When a pastor announces a chapter and starts reading through it ("Let's turn to Romans 8"), reading mode locks the queue to that book/chapter and uses voice navigation to advance — "next", "next verse", "previous verse", "go back", "next chapter", "previous chapter", "chapter N", "verse N", or "chapter N verse M".
This eliminates false positives from common phrases that sound like references but aren't, while the pastor is in expository mode.
No cloud booster yet
Earlier copy described an optional OpenAI/Claude "cloud booster"
that re-ranks ambiguous candidates. The settings store reserves
fields for openaiApiKey / claudeApiKey, but the booster itself
is not implemented in rhema-detection today. Detection runs
entirely locally.
Ensemble merging

Four strategies (direct, semantic, quotation, reading mode) emit candidate detections in parallel; the merger deduplicates, weights, and time-decays them into a single ranked stream that feeds the queue. Click to expand.
Each strategy emits candidate detections with confidence scores. The
ensemble merger (src-tauri/crates/detection/src/merger.rs)
deduplicates overlapping candidates, weights the sources, and applies
time-based decay so older candidates don't compete with fresh ones.
The output is a single ranked detection stream that feeds the queue.
Sentence buffering
The detector buffers transcript output into sentences (sentence_buffer.rs)
before passing them through the strategies. This reduces flicker —
partial transcript fragments don't trigger and then unfire as more
words arrive.
Sermon context tracking
Pastors quote across a sermon's arc. Rhema keeps a rolling sermon context of recent books and themes that the semantic strategy uses to disambiguate. If you've spent the last ten minutes in Romans 8, a passing reference to "by faith" is more likely Romans 8 than Hebrews 11.
Threshold tuning
The confidence threshold is exposed as a UI control and via the remote
control API (/rhema/confidence). Bumping it up reduces false positives
on noisy services; lowering it surfaces more candidates for manual
queueing.